Building Systems & Macrometa GDN From First Principles

Nov 07, 2022

First principles thinking is a powerful but under-used approach to building systems to solve complex problems. The basic idea of first principles thinking is to break down complex problems into essential elements that you know are true and then reassemble them from the ground up to solve the problem. In my experience, this approach enables one to unlock creativity and build innovative and robust systems.


Why do folks ignore this? Or maybe folks don’t know how to break problems into first principles and reassemble novel solutions to the problem. I had excellent results with applying first principles thinking to solve complex problems.
So thought I would share my approach in this post to show how one can build systems (and how we built Macrometa) by applying first principles in two different and complex domains — financial markets and edge computing.
Building a Trading System from First Principles
Let’s take investing/trading as it is a hot topic this year with inflation and recession worries. The problem is simple - I want to build a robust and profitable trading system that generates profits with less risk & not require too much of my time. Specifically, financial markets (equity, bonds, currencies, commodities, etc.) are complex and vast, so our task is to navigate this vast complexity and solve our problem.
Most retail investors have strategies to trade/invest in the markets. If we distill those strategies, often the first principles unwittingly are:
- Buy and pray
- Sell and cry
I’m sure we can do a little better and decompose financial market behavior into three first principles.
First principles for building a trading system
In any time frame (daily, weekly, monthly, etc.),
- Each market can move only in three ways: up, down, or sideways
- Some markets move opposite to other markets
- Some markets move faster than other markets in the same direction.
The above principles are simple and obvious, isn’t it? So, how do we build a profitable trading system from these first principles?
Each financial market can move only in three ways - Up, Down, and Sideways
Let’s take the first principle - Each market can move only in 3 ways: up, down, or sideways. Assuming we trade only on the long side (i.e., no shorting), it means we want to be in the market when it is going up and get out of the market when it is going down.
One way to do this is by using moving / rolling averages. Mathematically, a rolling average of the price will always be below the price, when the price is going up and vice versa when the price is going down.


So our system is -
- Buy Rule - Buy equities when the market closes above its moving average.
- Sell Rule - Sell equities and go to cash when the market closes below its moving average.
Some markets move opposite to other markets.
Let’s take the 2nd first principle - Some markets move opposite other markets. We know markets go through risk-on and risk-off periods. During risk-off periods, the capital flies from risk investments like equities to safe assets like US Treasuries, Bonds, etc. You can measure this behavior via rolling correlations.


So our revised system is -
- Buy Rule - Buy equities when the market closes above its moving average.
- Sell Rule - Sell equities and go to bonds when the market closes below its moving average.
System results
Following are the results of a trading system using the above rules.
- Equities Proxy: VFINX (Vanguard S&P 500 Index Fund)
- Bonds Proxy: VBMFX (Vanguard Total Bond Index Fund)
- Moving Average: 10-month Rolling Average.
- Test Duration: 1990 - 2022 (September). Timeframe: Monthly.


One can undoubtedly develop additional first principles to improve this system's results further. For example, using the 3rd principle to compare bonds and cash further reduces risk. You can also try this with other moving average lengths to see the stability of the returns. Finally, some skeptics might question why we’ve used a monthly timeframe and indexes are used in this system. The reason is simple - Inversion Mental Model.
Disclaimer: Anything in this post should NOT be taken as financial advice. Use it at your own risk.
Building Macrometa GDN from First Principles
Macrometa Global Data Network (GDN) is a platform for enterprises to build global systems of interactions and APIs to serve users around the globe instantly. In the past, only a handful of companies, like Google, Facebook, etc., could build these types of systems utilizing an army of PhDs and millions of dollars. Macrometa GDN gives enterprises an easy button to harness their data in real-time and, eventually, contextualize, replicate, monetize and share at a fraction of the cost and expertise.
A few years back, when my co-founder (Chetan) and I set out to build GDN, we faced a challenge: creating an edge native data & compute platform running across the globe in 100s of locations. Further, this platform must run seamlessly across multiple clouds, on-premise data centers, and telecom (5G) locations. None of the existing data or compute platforms could do this.
So our first step was to decompose the challenge into fundamental problems (aka first principles) that we know are true and need to be addressed. Then we solved these real problems and combined the techniques to build the GDN and edge compute you see today.
GDN First principles
The first principles that underlie the GDN platform are:
- Networks are unreliable across data centers.
- Networks have large latencies across data centers.
- Concurrent reads-n-writes across data centers.
- Query languages are CRUD operations on document fields.
- The table is a subset of a stream.
- Data is an asset.
- Bring compute to data
Networks are unreliable across data centers
Unlike networks within a data center, the networks across regions are unreliable. So the first step is to address this and create a reliable data replication mechanism across areas. To solve this, we built a replication system using append-only logs with a pull model in the same fashion as Apache Kafka and Apache Pulsar.
A key difference - In GDN, the geo-replicated streams are created and managed in a coordination-free manner. Also, initially, GDN used a SWIM-based gossip protocol over UDP to discover regions, but later on, a hierarchical peer-based discovery protocol replaced it. The primary reason is eliminating UDP to reduce headaches and the platform's footprint.


Networks have large latencies across data centers.
Have you ever tried to access servers running in the USA from Europe or Asia? If so, I don’t need to explain this principle. The results of a simple HTTP ping test between my server (San Jose, California, USA) and various AWS regions are shown below. The network latencies across regions are in triple digits compared to the single-digit latencies we see within a data center.

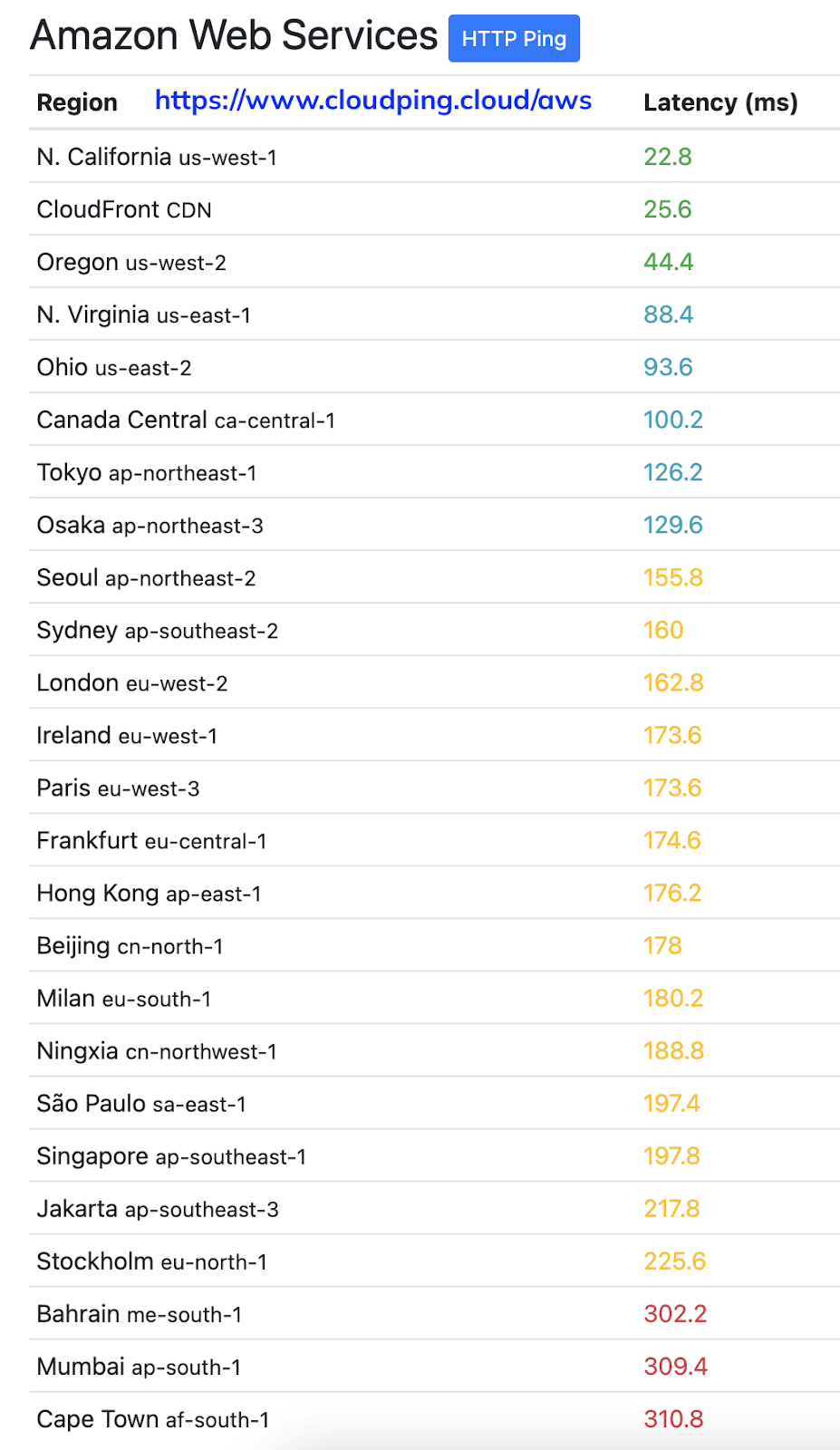
The challenge is that the current data platforms are designed to run inside a data center with single-digit millisecond network latencies. These data platforms use synchronized consensus protocols like Zabber, Paxos and Raft, etc., which are chatty and require coordination between the regions. So when you run these platforms across multiple data centers, you will have the following problems -
- The operations incur significant latencies to complete because of synchronization between regions.
- The operations frequently fail because of unreliable networks between regions. The more regions, the more frequent the failures are.
- The operations create significant network traffic because of protocol chattiness.
Macrometa GDN eliminates these problems using a coordination-free architecture, i.e., CRDTs are used for convergence across data centers. More details on this are in the next section.
This coordination-free architecture allows GDN to scale to many data centers. Also, it enables GDN to serve reads-n-writes with low latency and no coordination with other data centers.
Concurrent reads-n-writes across data centers
Conflict-free Replicated Data Types (CRDTs) are data structures that can be updated without expensive synchronization/consensus. They allow data to be concurrently updated on several replicas, even while offline, and provide a robust way to merge those updates into a consistent state. In this regard, CRDTs differ from the algorithms used by Google Docs, Trello, and Figma, which require all communication between users to flow via a server.
GDN incorporates CRDTs by decomposing a database into its most minor elements (aka first principles):
- A database is a collection of tables.
- A table is a collection of documents.
- A document is a collection of fields.
- A JSON document is a collection of data types - string, boolean, number, list, or object.
GDN uses RICE (Real-time Intelligent Convergence Engine) to handle insert, update or delete operations on a JSON document. The RICE engine generates CRDT operations for any changes to a JSON document. Similarly, it applies CRDT operations to the local document state and converges to a consistent state mathematically deterministically. The CRDT operations are replicated across all data centers via persistent streams. Similarly, GDN uses Vector Clocks to tag the CRDT operations for establishing causal relationships between changes across data centers.


A big challenge when using CRDT is garbage collection of the ops history log. The history log of a document grows with each insert, update, or deletion of a field in the document. Some platforms try to do garbage collection by coordinating across data centers. But that is not scalable and introduces the problems described in the previous section. Instead, GDN uses an innovative co-ordination free garbage collection algorithm to keep the document (aka history log) from growing unbounded. You can read more about it under the technology section on the Macrometa website.
Currently, only some systems provide CRDT data structures. Providing a whole database built on the CRDT mechanism is more complex. Unlike individual data structures, to give a CRDT database, the database query language (ex: SQL, C8QL, etc.) needs to be translated in real-time to applicable CRDT operations. This is what GDN does to provide a database abstraction to users while using CRDTs and ops logs internally.
For example, an update SQL query like the one below will be translated in real-time by GDN into CRDT operations shown below:
**SQL Query:**UPDATE CustomersSET ContactName = 'Alfred Schmidt', City= 'Frankfurt'WHERE CustomerID = 1;
**CRDT OpLog:**((1,0,0), UPDATE, ContactName=Alfred Schmidt)((2,0,0), UPDATE, City=Frankfurt)Where (x,y,z) is a Vector Clock.
When a user issues an INSERT, UPDATE or DELETE query (aka WRITE queries), GDN converts these queries internally into a series of CRDT Operations. Then these CRDT operations are geo-replicated asynchronously to applicable data centers for local processing. Each data center applies the CRDT transformations and incrementally updates local materialized views. READ queries are served by the materialized view engine for low latency. Various types of indexes (hash, skiplist, TTL, geo-spatial, full text ) are supported on these materialized views to reduce the read latencies further.


Similarly, GDN supports multiple data models (key-value, docs, graphs, search) again by leveraging first principles:
- KeyValue Store —> A set of JSON documents with a primary key for each document. Supported operations - get, set, delete
- Document Store —> A set of JSON documents with a primary key for each document. Supported operations - Query Language (SQL), Indexing & Transactions.
- Graph Store —> A set of JSON documents to represent a graph (i.e., each vertex and node of a graph is a document). Node documents contain from and to fields. Supported operations - Query Language, Indexing, Transactions, Graph Functions, etc.
- Search Store —> A reverse index on a set of JSON documents. Supported operations - Query Language, Indexing, Search Functions, etc.


Most data platforms are monolithic systems. GDN is built as layers, each building on top of the previous layers. The layer model enables GDN to support multiple query interfaces easily. GDN supports C8QL, SQL, Dynamo, and Redis query languages as plugins. More on the way. So the revised picture looks like the one below.


Tables are subsets of Streams
Today most folks use separate data platforms for data-at-rest and data-in-motion. Example - Databases for data-in-motion and Stream Processing systems for data-in-motion. The data is the same whether it is data-at-rest or data-in-motion.
So why do developers have to use four different platforms (i.e., DB, Streams, Search, Stream Processing) and waste their time wiring these platforms together, spend days to program and ensure the data is consistent across all platforms, etc.? Similarly, why are architects forced into building complex architectures, and why do operators have to manage & maintain a forest of products?
Like most readers of this post, I was that developer & architect. I paid the tax to deliver my stuff. So naturally, this question was on top of my mind while architecting GDN. Consider a table with one document and a stream with one document. Is there any difference between them? No. Say we have an update to the document. The table contains one document with the latest change, whereas the stream contains two documents. In other words, the table is nothing but compaction of the stream contents to reflect the latest state of a document.


In GDN, every table is also a stream. This opens up influential developers' capabilities and eliminates the need for complex architectures that look like spaghetti balls. A developer can now query the data when it is at rest (aka tables) and the data when it is in motion (aka stream processing). Also, a developer can join tables, join streams or join streams & tables as part of their queries. This is a very nice power to have. Please refer to the complex event processing section of GDN docs for more information. So our revised GDN architecture looks like the below.


Data is an asset
There is a good reason we need to consider this as a first principle in designing data platforms for the future. Data is the new oil, and every nation would like to control it as soon as they can figure out a way to monetize it (or use it to control the population for authoritarian regimes). Also, many citizens (including myself) prefer privacy and control over their data. GDPR, California & India data laws are just a start.
Currently, the data regulation and compliance solution are to set up dedicated clusters in each applicable region and wire them together. It is a very cumbersome and expensive way. Ideally, the data platform should enable developers to do geo-pinning and geo-fencing of data & compute efficiently. Unfortunately, most databases, streaming systems, and stream processing platforms are not designed for this.
GDN is an edge native platform. The bottom-most layer of GDN is about discovering data centers and creating geo-replicated streams between them on the fly. (Please see section - Networks are unreliable across data centers). So we extended this bottom layer to create a streaming mesh overlay between selected regions on the fly, providing containment to all higher layers. We call these GeoFabrics.

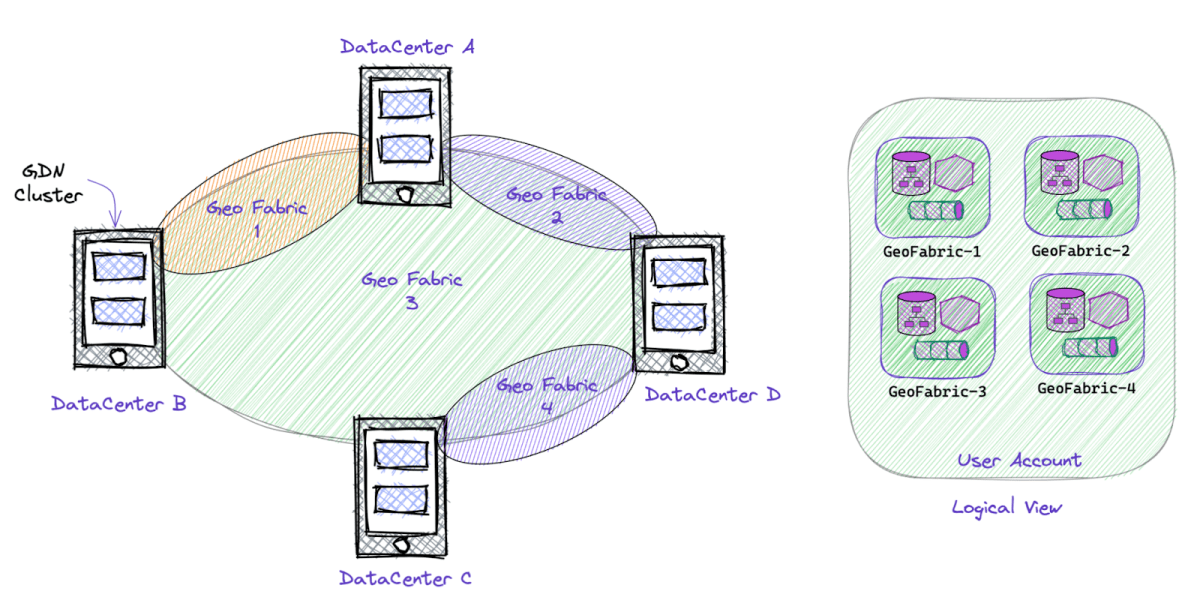
GeoFabrics automatically geo-pin the data, streams, stream processing, and compute to only regions attached to that geo-fabric. A user can create GeoFabrics using a subset of regions, all based on their criteria and not pre-generated (such as the US, Europe, or Asia, for example).
There are three advantages of GeoFabrics for GDN users:
- Comply with local data regulations (such as GDPR)
- Reduce read/write costs associated with global replication
- Create needed geo-fabrics with a click of a button
Bring compute to data
The modern web we know today was possible because Akamai, the grandfather of CDNs, pioneered the idea of moving static data to the edge. Likewise, the cloud we know today was possible because AWS pioneered moving data to hyper-scale data centers that host enormous computing power. In both cases, it was data that was moved to compute.
So why do we need to move the compute to data? Four reasons why it is better & easier to move compute to data instead of moving data to compute:
- Today, data is an asset that every enterprise wants to protect and monetize.
- Also, today many nations want to ensure the data does not leave their borders and require enterprises to comply with regulations and privacy laws.
- Similarly, today the amount of data generated is astronomical compared to 10-20 years ago.
- Similarly, computing is temporary and available everywhere today.

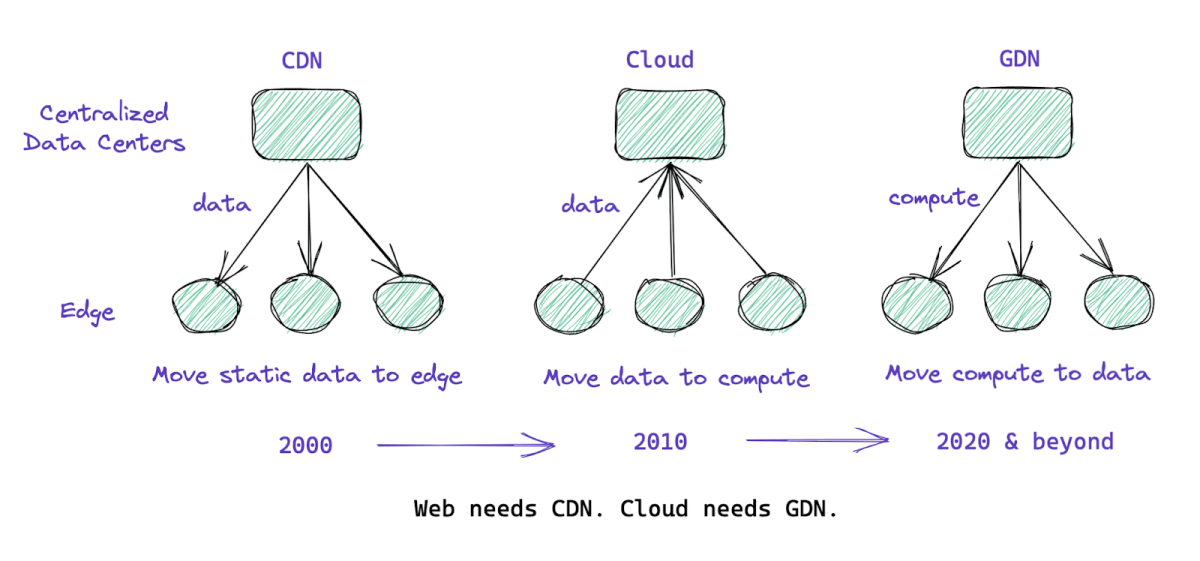
The industry started taking steps in this direction by providing serverless functions-as-service like AWS Lambda Edge Workers, Akamai Edge Workers, etc. But this is not sufficient for three reasons -
- The backend for most enterprise apps is microservices and daemon services.
- Most enterprise apps require stateful computing.
- Enterprises prefer compute-on-demand and geo-pinning to a subset of locations for compliance & cost-reduction purposes.
Macrometa GDN already has rich orchestration & data management capabilities. So the next step was to enable users to bring compute to data around the globe with a click of a button eliminating the need for complex & costly operations. GDN provides the compute orchestration and colocation of computing & data around the world via its query workers, stream workers, functions as service, and containers as service.


Wrapping up…
From time to time, people ask us how Macrometa GDN compares to other NoSQL, Streaming, or Stream processing systems. Maybe we have done an excellent job abstracting all the underlying technologies like CRDTs, materialization engine, multi-model, geo-replication, etc. GDN is fundamentally different architecture from current data platforms and is edge native. Most data platforms are not edge-native and cannot scale geographically nor provide capabilities like GDN.
This post provides a good set of first principles and ways of thinking for readers interested in building geo-distributed data platforms. While your design and implementations will vary, the problems needed to be solved are the same to be an edge native platform. Similarly, I hope this post helps readers evaluate geo-distributed data platforms better.
Finally, I hope this post provides good examples of building novel and innovative systems starting from the first principles.
P.S - This post is a part of our Developer Week series, whose theme is, “The future is edge native: Building on the cutting edge with Macrometa and friends.” Join us at Developer Week to read more such exciting posts. And if you want to see Macrometa in action, sign up for a demo today.


