Apache Spark Vs Hadoop
Chapter 7 of Event Stream Processing
Apache Spark vs Hadoop
Big data processing can be done by scaling up computing resources (adding more resources to a single system) or scaling out (adding more computer nodes). Traditionally, increased demand for computing resources in data processing has led to scaled-up computing, but it couldn’t keep up with data growth, so scaling out or a distributed processing approach has taken over in the last decade. It has evolved from processing data at rest (batch processing) to stream processing and complex event processing (CEP).
Hadoop was one of the pioneers in leveraging the distributed system for data processing. Later, Apache Spark overcame the shortcomings of Hadoop, providing features such as real-time processing, reduced latency, and better abstraction of distributed systems. Both are widely used in the industry.


Fig 1. Scale-up or vertical scaling vs. scale-out or horizontal scaling
In this article, we’ll compare Hadoop and Apache Spark across different vital metrics.
Table 1. Comparison of Apache Hadoop and Apache Spark
| Apache Hadoop | Apache Spark | |
|---|---|---|
| Data Processing | Batch processing | Batch/stream processing |
| Real-time processing | None | Near real-time |
| Performance | Slower, as the disk is used for storage | 100 times faster due to in-memory operations |
| Fault-tolerance | Replication used for fault tolerance | Checkpointing and RDDs provide fault tolerance |
| Latency | High latency | Low latency |
| Interactive mode | No | Yes |
| Resource Management | YARN | Spark standalone, YARN, Mesos |
| Ease of use | Complex; need to understand low-level APIs | Abstracts most of the distributed system details |
| Language Support | Java, Python | Scala, Java, Python, R, SQL |
| Cloud support | Yes | Yes |
| Machine Learning | Requires Apache Mahout | Provides MLlib |
| Cost | Low cost, as disk drives are cheaper | High price since a memory-intensive solution |
| Security | Highly secure | Basic security |
Parallel vs. distributed processing
Comparing Apache Spark and Hadoop requires understanding the difference between parallel and distributed computing. The data processing community adapted different architectures as the trend changed from vertical scaling to horizontal scaling. There are three different taxonomies for parallel architectures.


Fig 2. Taxonomy of parallel architectures (source)
The shared-nothing approach doesn’t share any resources—each node is independent. Shared disk taxonomy has a shared disk, while shared memory has both shared disk and memory.
Distributed computing is the simultaneous use of more than one computer connected over the network to solve a problem, similar to a shared-nothing architecture. Parallel computing, in comparison, is a shared memory architecture involving the simultaneous use of more than one process to solve a problem.
Hadoop uses distributed computing concepts while Apache Spark leverages both distributed and parallel computing. Parallelization and distributed come with their own challenges, so it’s vital to choose the right technology for your use case. Some of the challenges include the following:
- How to ensure fault tolerance in a distributed cluster
- How to make it easy for developers to write distributed programs
- How to distribute computation tasks to different nodes
Apache Hadoop
Hadoop is an ecosystem that provides different tools for parallel data processing. It introduced the concept of leveraging scaled-out commodity hardware compared to traditional scaled-up data processing systems. Furthermore, it overcame the challenge of handling unstructured data such as text, audio, videos, and logs.


Fig 3. Apache Hadoop architecture (source)
Hadoop is comprised of the following modules:
- Hadoop Distributed File System (HDFS): A highly fault-tolerant file system designed to run on commodity hardware.
- Yet Another Resource Negotiator (YARN): A resource manager and job scheduling platform that sits between HDFS and MapReduce. It has two main components, a scheduler, and an application manager.
- MapReduce: A parallel data processing framework for large clusters.
MapReduce
MapReduce is a shared-nothing architecture for big data processing using distributed algorithms while leveraging a commodity hardware cluster. It takes care of data distribution, parallelization, and fault tolerance transparently while providing abstractions for the developer. MapReduce supports batch processing on big datasets and executes algorithms in parallel. Since storage and computing are on the same node, it also provides good performance.
MapReduce processes the data in three main stages—Map, Shuffle, and Reduce. First, the input file is distributed, and inputs are sent to each parallel instance. Second, the Map task operates on a single HDFS block and generates an intermediate key/value pair after the process. Third, the Shuffle stage consolidates all the map task outputs and sorts them based on a key. Finally, the Reduce task combines and reduces all the intermediate values associated with the same key.


Fig 4. Different steps of MapReduce architecture; each color represents an element belonging to a particular key group
Automated eCommerce SEO Optimization
- Prerender your website pages automatically for faster crawl time
- Customize waiting room journeys based on priorities
- Improve Core Web Vitals using a performance proxy
Apache Spark
Apache Spark is an open source data processing framework that was developed at UC Berkeley and later adapted by Apache. It was designed for faster computation and overcomes the high-latency challenges of Hadoop. However, Spark can be costly because it stores all the intermediate calculations in memory.
Apache Spark supports batch, stream, interactive, and iterative processing. Spark streaming also lets you stream and process the data in real-time. It also has features that Hadoop doesn’t offer, such as running SQL queries and performing complex analytics using machine learning and graph algorithms. Spark is backward compatible with the existing Hadoop ecosystem components, such as HDFS and HBase, which makes it relatively straightforward to integrate older data systems.


Fig 5. Spark application architecture
An Apache Spark application consists of a driver process and a set of executor processes. The driver process is the heart of the application and orchestrates code execution on the executors. The driver process also coordinates user input and maintains information about the application. Apache Spark jobs are directed acyclic graphs (DAGs) composed of input data sources, operators, and output data sinks.
Apache Spark uses the resilient distributed dataset (RDD)—a distributed memory abstraction. RDDs are fault-tolerant, immutable data structures that support the parallel processing of events across the cluster. An RDD is divided into several partitions stored on different nodes of a cluster.


Fig 6. An RDD, a collection of events spread across a cluster
Comparison of Apache Hadoop and Apache Spark
Now we will discuss the different vital metrics in detail and compare them for Hadoop and Apache Spark.
Performance
One of the key differentiators between Apache Spark and Hadoop is performance. It’s unfair to compare their performance directly because they use different types of storage due to their architecture. Hadoop stores the results of each intermediate step on disk, but Apache Spark can process in-memory. Although Hadoop reads data from local HDFS, it cannot match Spark’s memory-based performance. Apache Spark’s iterations are 100 times faster than Hadoop for in-memory operations and ten times quicker for on-disk operations.

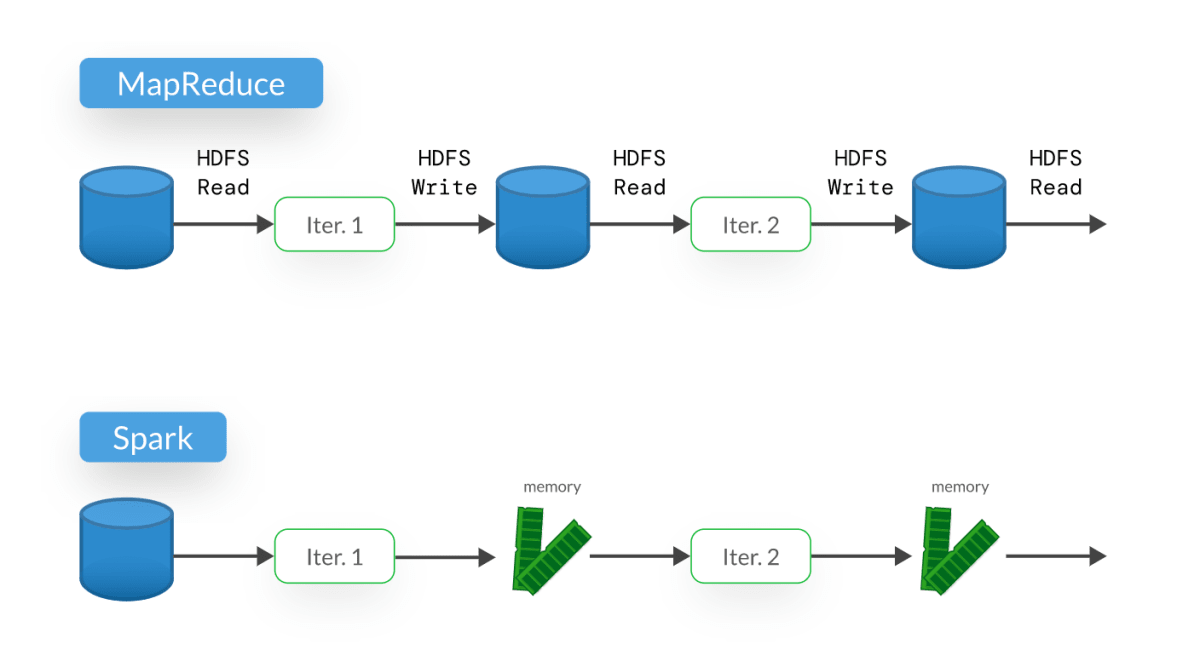
Fig 7. Traditional MapReduce writes to disk, but Spark can process in-memory
Data processing
Hadoop offers batch processing, while Apache Spark offers much more. In addition, both frameworks handle data in different ways: Hadoop uses MapReduce to split large datasets across a cluster for parallel data processing, while Apache Spark provides real-time streaming processing as well as graph processing. However, Hadoop needs to be combined with other tools to achieve such functionality.
Real-time processing
Hadoop doesn’t offer real-time processing—it uses MapReduce to execute the operations designed for batch processing. Apache Spark provides low-latency processing and delivers near-real-time results via Spark Streaming. It can read real-time event streams with millions of events per second, such as the stock market, Twitter, or Facebook streams.
Cost
Spark and Apache Hadoop are both open source, so there is no licensing cost involved in their use. However, development and infrastructure costs need to be taken into consideration. Hadoop relies on disk storage and can be used with commodity hardware, making it a low-cost option. In contrast, Apache Spark operations are memory-intensive and require a lot of RAM, which increases the cost of the infrastructure.
Scheduling and resource management
Apache Spark has Spark Scheduler, which is responsible for distributing the DAG into stages. Each stage has multiple tasks scheduled to computing units and executed by the Spark execution engine. Spark Scheduler with Block Manager (a key-value store for blocks of data in Spark) takes care of job scheduling, monitoring, and distribution in a cluster.
Hadoop doesn’t have a native scheduler and needs to use an external one. It uses YARN for resource management and Oozie for workflow scheduling. However, YARN only distributes the processing power, so the application state needs to be managed by the developers.
Fault tolerance
Both frameworks provide a fault-tolerant mechanism and take care of failures transparently, so users don’t have to restart applications in the case of failure. However, they have different techniques to handle failures.
Hadoop has fault tolerance as the basis of its operation. The master node keeps track of all the nodes in the system; if a node dies, its tasks are delegated to the other nodes. Also, each data block is replicated on multiple nodes. When failure happens, it resumes the operation by replicating the missing or faulty block from other locations.
Apache Spark manages fault-tolerance on the basis of each RDD block. It has the lineage of the RDD in the DAG, including its source and the different operations performed. In case of a failure, Spark can regenerate an RDD all the way up to its inception. Additionally, it supports checkpointing as well, similar to Hadoop, to reduce the dependency on RDDs.
Security
Hadoop is more secure than Apache Spark. Hadoop supports multiple authentication mechanisms, including Kerberos, Apache Ranger, Lightweight Directory Access Protocol (LDAP), and access control lists (ACLs). It also offers the standard file permissions on the HDFS. In contrast, Apache Spark has no security by default, making it more vulnerable to attacks unless configured adequately. In addition, Spark only supports authentication via shared secret passwords.
Programming language and ease of use
Apache Hadoop is developed in Java and supports Python as well. Apache Spark is developed using Scala and supports multiple languages, including Java, Python, R, and Spark SQL. Thus, it helps developers by choosing the programming language of their choice to avoid a learning curve.
One significant advantage of Apache Spark is that it offers an interactive mode for development, allowing developers to analyze data interactively using the programming language of their choice: Scala or Python. Furthermore, it is easy to program since it offers many high-level operators for RDD. On the flip side, Hadoop development is complex as developers need to understand the APIs and hand-code most operations.
Machine learning
Hadoop doesn’t have native machine learning libraries. Apache Spark provides machine learning support via MLlib. MLlib is easier to use and get started with for development on Spark for machine learning use cases due to excellent community support. In addition, it’s faster due to in-memory iterations.
Apache Mahout is used for machine learning development for Hadoop as Mahout uses MapReduce. However, performance is slow, and data fragments can be too large and become bottlenecks. Furthermore, Apache Mahout’s recent releases use Spark instead of MapReduce.
Conclusion
Hadoop offers basic data processing capabilities, while Apache Spark is a complete analytics engine. Apache Spark provides low latency, supports more programming languages, and is easier to use. However, it’s also more expensive to operate and less secure than Hadoop. In addition, both platforms require trained technical resources for development. Besides these two frameworks, developers can use different frameworks for big data processing like Apache Flink and Apache Beam.
It is crucial to have a deep comprehension of the technology landscape, whether you are creating applications or assessing ready-to-go industry solutions offered by Macrometa. By attaining a comprehensive understanding of these technological choices, you can make informed decisions and effectively utilize the appropriate solution to address the specific requirements for streaming and complex event processing.
Macrometa offers a hyper distributed cloud platform with streaming and CEP (complex event processing) capabilities, a pay-as-per-usage model, and robust documentation. In addition, Macrometa’s Global Data Network (GDN) is a fully managed real-time and low-latency materialized view engine that enables a pipeline based on your requirements. You can request a trial here. Explore our ready-to-go industry solutions that address the most complex problems.
Is your website ready for holiday shoppers? Find out.
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.