Data Ingestion: Tutorial & Best Practices
Chapter 6 of Distributed Data
Data ingestion is the process of aggregating and importing raw data from different sources, organizing it into a uniform structure and moving it to a single destination (landing stage, storage medium, or application) to make it available for short-term uses such as querying or analytics.
Understanding the underlying technology options is crucial, whether you are developing applications or considering ready-to-use industry solutions from Macrometa. The speed at which you can ingest, transform, and synchronize data directly impacts the efficiency of your data processing and analytics. This becomes especially important in industries such as logistics or travel/hospitality, where you often deal with diverse data from different sources, and the customer experience relies on seamless and fast data integration.
Common examples of data ingestion include:
- Processing CSV files with customer orders into a database.
- Consuming and storing the response data from an API request.
- Real-time data ingestion and processing of event messages from a food delivery app.
This chapter will explore data ingestion with a special focus on real-time data. We’ll briefly cover the data ingestion process and key steps such as data processing, transforming, storing, and throughput. Then, we’ll dive into a deeper look at real-time data ingestion, NoSQL, and distributed architectures.
Data ingestion - key topics
The table below provides a quick overview of the data ingestion topics covered in this article.
| Topic | Examples |
|---|---|
| Data Sources and Processing Data | CSV, Batching, Event streams |
| Transforming Data | ETL, ELT |
| Storing Data | NoSQL vs. RDBMS, Postgres |
| Throughput | Storage requirements, distributed architecture |
| Real-time Data Ingestion | All of the above |
Overview
Data ingestion is the first step in collating data from everywhere and making it usable for data teams and business users. It's used whenever we have multiple data sources and need to bring these disparate datasets together for business use.
For example, a retail chain might want to combine data about customer actions on a website or app, the customer’s purchase history, product inventory in different locations, and trending products to make more attractive offers and recommendations.
At its simplest, data ingestion is about gathering information from many different sources in one single place - with little effort and fewer overheads. Data pipelines are used to aggregate data from various sources and transport it to wherever it needs to be used - thus streamlining data delivery across different systems and the entire organization.
The data ingestion process is the same for both structured and unstructured data, and can be implemented either in real-time or in batches - or a combination of both. While the essential difference between batch processing and real-time processing is the time when data is processed (later vs. immediately) - the output, uses and business impact of both are vastly different.
But, before we get into that, let’s quickly consider the key elements of a data ingestion framework:
- Sourcing data
- Processing
- Transforming
- Storing and throughput
Data sources
There are a variety of potential sources for data ingestion. Data can come from multiple CSV files, RESTful APIs or scraping of websites. In the case of real-time data, it could be webhooks (automated event-driven messages), or event streams.
Quite often, data is aggregated (a pile of fixed-size data) and processed in batches, which usually takes a fixed amount of processing power. However, when working with real-time sources of data, such as event streams and messaging, we need to process it immediately - so that the value of the data isn’t lost over time. This requires affordable scalability to handle huge data volumes and any spikes in events/messages.
Processing data - batching and event streams
There are several different methods for data processing. You can:
- Process data in batches (batch processing)
- Process events as they come in (streaming)
- A combination of batch and streams (lambda)
Streaming ingests data continuously - with each record being processed as quickly as it’s sourced - making it a resource-hungry process. But, it makes data available for analysis in real-time data and is essential for time-sensitive applications.
Batch processing updates data at longer intervals and optimizes the use of computing resources.
These methods aren’t mutually exclusive - they’re all useful as parts of a data ingestion pipeline.
Here’s an illustration of each process:

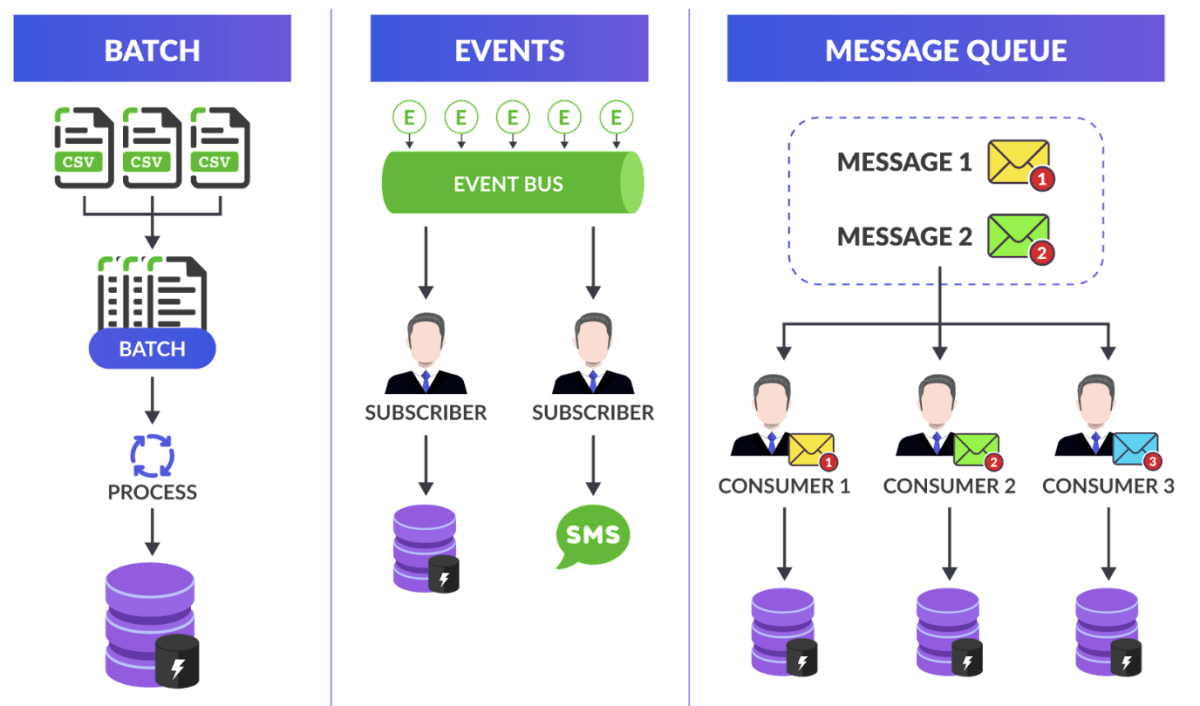
Batch processing, event streaming, and message queues as part of a data ingestion pipeline.
Batch processing aggregates data to process in batches, to reduce the load on computing resources and process data in a consistent manner.
Events processing captures events in an event bus in order to provide event streams to subscribers.
Message queues systematically process messages by delegating messages to consumers.
Since most businesses use both batch processing and streaming technologies, they need a versatile processing architecture to process, store and orchestrate the flow of data and services.
Enterprises can build their own data pipelines or use purpose-built managed solutions - such as Macrometa’s Global Data Mesh, Apache Spark, Kafka and more. While Spark is best for batching to process large data sets, Kafka is ideal for event streaming. Macrometa combines both streams and tables - treating streams as real-time user tables - to allow data interactions in real-time, in-motion fashion with streams, via pub/sub, and querying using request-response with SQL. This makes Macrometa highly flexible, adaptable, and cost effective.
Transforming data
Sometimes, we need to change the data we aggregate. In other words, we need to transform the data. Extract, transform, load (ETL) is the process of doing this “in transit” before storing our data. Extract, load, transform (ELT) is the process of storing the raw data and transforming it later.
For example, when processing CSVs, you might want to strip unwanted characters or combine columns before inserting them into your database. That is a transformation that must be performed upon ingestion so it would be considered an ELT process.
In another example, real-time events may be ingested and stored at “wire speed” (meaning as soon as they are produced) to avoid ingestion delay. Later, a separate process may go through the events and de-duplicate them which would categorize this ingestion process as ETL instead of ELT.
Storage and throughput
There are various options for storing data for different use cases and requirements. Traditional relational database management systems (RDBMS) are ideal for writing complex queries since data is stored in a rigid relational table structure. The downside of an RDBMS is operational overhead and less out-of-the-box throughput.
Another storage option is a column-oriented DBMS (database management system) - used similarly to RDMS as the destination for batch processing - with speed advantages when ingesting and querying data later.
NoSQL supports simple queries with less operational overhead and is usually developed with distributed architecture in mind. Therefore, NoSQL stores can handle more concurrent writes and provide greater throughput than RDBMS.
NoSQL is also better suited for high-volume requests (such as real-time data). The Macrometa Global Data Mesh provides all the benefits of a NoSQL database and allows applications to store and query operational data in a variety of ways, including as documents, graphs, key/value pairs, streams, and through natural language search.
Check out this StackOverflow thread for a deeper dive into the NoSQL vs. RDBMS discussion.
Real-time data ingestion
Real-time data ingestion is characterized by a constant stream of mostly unstructured data (in huge volumes) that needs to be processed quickly - before it loses value. All this data must be consumed, formatted, and analyzed at the same speed it’s generated, i.e. in real-time.
It’s best suited to situations that demand instant action such as stock market transactions, payment processes, fraud detection, self-driving vehicles, and more.
Millions of data points coming in real-time requires concurrent processes that can handle all the requests, as well as a storage solution that can handle an equally high number of concurrent writes.
This poses two challenges - complexity and cost.
Macrometa’s geo-distributed event data processing allows real-time stream processing of millions of events in milliseconds around the world for high performance, low-latency use cases like OTT video services ad serving, or fraud detection for financial services. It also makes it more affordable, faster and easier to ingest data in real-time than centralized clouds.
Event streaming vs messaging
Real-time data is often associated with the terms ‘event streaming’ and ‘messaging’, which can be confusing.
Both approaches are used to implement asynchronous communications between services/applications and the terms are often used interchangeably.
Here’s a simple breakdown of event streaming vs. messaging to help make things clear.
Event streaming (Pub/Sub)
- Publishers publish events to topics; subscribers subscribe to topics
- Publishers stream a log of events to multiple subscribers
- ‘Subscribers’ pull the latest events from a stream and keep a record of pulled events
- Events are not ‘consumed’
Messaging
- Producers send messages to a queue; consumers consume messages from the queue
- Producers send individual messages to be immediately consumed
- ‘Consumers’ wait for a message, acknowledge the message, and the message is removed from the queue post-acknowledgment.
Macrometa Streams gives enterprises the ability to work with both Pub/Sub and messaging queues together with multiple subscription models. It drives seamless geo-replication of messages across regions with very low publish and end-to-end latency.
Event driven architecture
Real-time data architecture is sometimes referred to as ‘event driven’. To manage real-time events, you need an event bus to handle incoming events, and then the event bus can distribute events to subscribers/consumers. From there, you can handle each event by saving directly to a high-performance database or passing the event along to another service like a messaging queue.
Scalability for processing events and messages can be achieved in two ways:
- Pub/sub using topics to reduce the overhead of routing individual messages, since publishers and subscribers can operate independently and subscribers can subscribe to a topic to get relevant messages from the event bus.
- Message brokers handle queuing of messages and distributing messages to consumers. The workload is distributed, and consumers can scale to meet demand
The advantages of messages are the even distribution of work among consumers and the ability to acknowledge events.
The advantages of subscribers are that they keep a record of events received and will only request events when they have space available.
Most big data ingestion platforms use some amalgamation of these concepts to describe their event driven architecture. Here’s one example of how it might work:

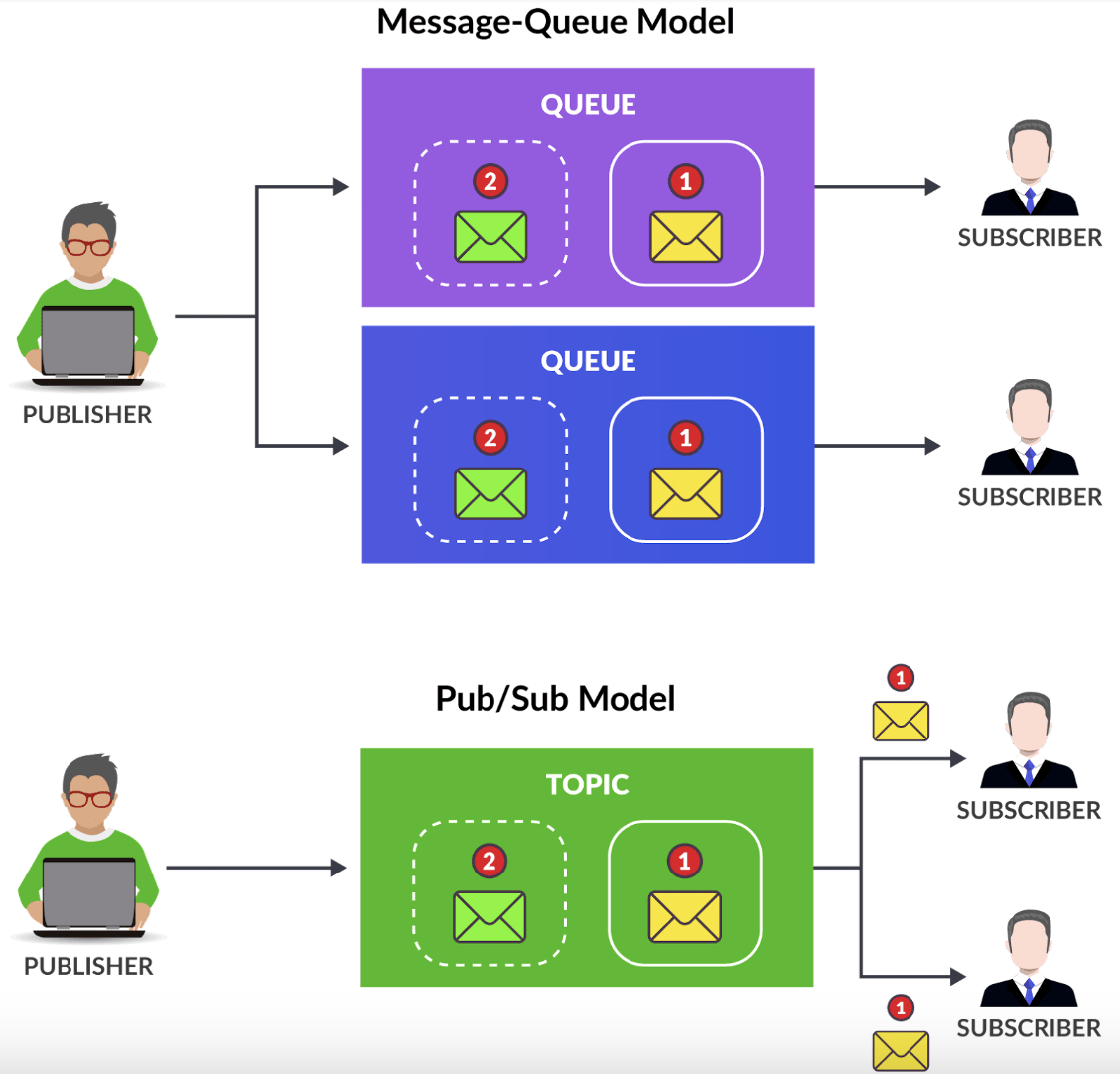
Event-driven architecture with Pub/Sub. (Source)
To store a high volume of real-time events, you need a storage system with high throughput. This is best achieved using a distributed architecture, with multiple nodes that can handle a large number of concurrent commits to a database. While an RDBMS can support distributed clusters (e.g., with sharding), NoSQL is purpose-built for distributed systems. Another solution is file system-based storage which can handle a large number of writes.
So the main issues of real-time data ingestion come down to:
- Handling and processing a large number of incoming events.
- Storage input output operations per second (IOPS) and the number of concurrent processes that can share the same storage.
Conclusion
In summary, data ingestion revolves around patterns and models for capturing, transferring, and storing data. Real-time data ingestion focuses on volume of data and the number of incoming real-time events. You need to be able to handle a large number of requests and a large number of writes.
It all comes down to physical processing power constraints, latency thresholds, and which storage works best for your data. There are different processing requirements for batch processing a trove of CSVs over a week versus processing millions of requests per second every day. So it’s worth doing your homework to see if you can roll your own solution, or use a more managed solution to architect your real-time data ingestion.
Many platforms, like Macrometa Global Data Mesh, Apache Kafka, Azure Event Hubs and others, offer managed real-time data ingestion. The advantages of these platforms are that they manage scaling and distributed data storage for you. For many use cases, these platforms provide all the required functionality with a fraction of the work required to build a custom solution. Macrometa also offers ready-to-go industry solutions that solve the most challenging operational problems.
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.