Sharding vs Partitioning
Chapter 4 of Distributed Data
The Internet of Things (IoT), Artificial Intelligence, Machine Learning, and other modern technologies have one thing in common: big data. And this data just gets bigger and bigger. Database scalability, therefore, becomes crucial for applications that use these technologies.
In simple terms, database scalability refers to the ability of a database to add and remove resources based on changing demands. Naturally, you may be under the impression that a scalable database would address big data storage problems — as you scale resources, you can store more data, right?
But it’s querying and retrieving the data that’s the problem. After all, you don’t want to scan through billions of rows of data to locate just one line that matches your query. You need a more elegant solution to crunch through the data, and this is where partitioning and sharding come into the picture.
Whether you are building applications or considering ready-to-go industry solutions from Macrometa, having a comprehensive understanding of the underlying technology options is essential. In today's digital landscape, where the volumes of data continue to grow exponentially, and projections indicate the potential scaling to a trillion events per minute, effective data management has never been more critical.
This chapter will describe partitioning and sharding, highlight their differences and similarities, and cover the best use cases for each.
Summary of key concepts
The table below summarizes the significant differences between sharding and partitioning for your reference. We will explain these terms in detail further on.
| Dimension | Sharding | Partitioning |
|---|---|---|
| Data Storage | On separate machines | On the same machine |
| Scalability | High | Limited |
| Availability | High | Similar to unpartitioned database |
| Number of Parallel Queries | Depends on the number of machines | Depends on the number of cores in the single machine |
| Query Time | Low | Medium to Low |
Partitioning and sharding
Partitioning
Partitioning is a general term for splitting a database along a specific axis to produce multiple smaller databases. You can partition a database:
- vertically: i.e., splitting the data, so the smaller databases have the duplicate rows, but different columns
- horizontally: i.e., splitting the data, so the smaller databases have the same columns, or the same schema, but different rows
Both vertical and horizontal partitioning have their advantages. Consider a database that has a substantial varchar column (such as an address) or a JSON column (such as meta-data/raw data), or a blob column (such as an image or file).
The varchar column may not be part of most queries. It makes sense, then, to partition the table vertically. The table is now split, with the varchar/JSON column and other rarely accessed columns residing in one partition. Frequently accessed columns will now live in the other partition. This separation will speed up query execution, particularly queries that access the frequently accessed columns, as they now scan fewer data items.
Similarly, let us suppose that you have time series data (location coordinates in an IoT-based vehicle tracking application), and your usual queries fetch data containing information for a single day. Then, it makes sense to partition the data horizontally based on time, so each partition has data corresponding to one day. Queries can now only scan a single partition and don’t need to go through the bulk of the data, significantly reducing execution time.
Another way to think of horizontal and vertical partitioning is this:
- horizontal partitioning replicates the schema of one table to multiple tables, distributing data among them based on a key (the key was “day” in the example above)
- vertical partitioning divides a table schema and divides the data accordingly
Example
Here we can see our original data:
Here is our vertical partition (separating the bulky, less frequently queried raw_data column in a separate table):
Here is the data with a horizontal partition (with device_id as the key, i.e. data is grouped by device_id, so that queries for a single device access only one partition):
For non-relational databases (key-value pairs, NoSQL databases, document-based databases, etc.), horizontal partitioning is more intuitive and practical. Vertical partitioning will not work in several cases, as the data does not have a fixed schema.
Sharding
Sharding is a subset of partitioning. Before we explain sharding and what makes it unique, let’s first examine how data scaling works. As your volume of data increases, you may also need to increase the storage capacity of your database. You could perform vertical scaling (add additional CPU, RAM, storage, etc.) or scale horizontally (add more nodes or machines to your server). We could also describe these choices as either scaling up or scaling out.
Sharding is the horizontal partitioning of data where each partition resides in a separate node or a separate machine. Each machine has its CPU, storage, and memory. Therefore, the query performance improves significantly, and multiple queries can run in parallel on different machines.
Each node is called a shard, and the data is inserted into shards based on a shard key. This key can be composed of one or more columns. For example, if the telematics data of a GPS tracking device are stored in a database, then (device_id, day) could constitute the shard key, and the data for each day (for each device) is stored in a separate shard.
Note that sharding and partitioning differ from replicating (copying) data. While horizontal partitions or shards can have the same schema, each partition/shard contains different data, depending on the key used for inserting the data. You may replicate data across shards for better availability and redundancy, but that’s not the same as database sharding.
Use cases
Sharding and partitioning share many use cases (after all, one is a subset of the other), and some examples have already been discussed, but let’s consider a few more:
- a website displaying pandemic information may partition or shard data by country or region, as most queries will retrieve information based on specific locations
- a stock market analytics firm may partition data by company, or by (company, day) if it wants to perform even granular technical analysis.
- an IoT company that manufactures smart home appliances might shard data by device so that a fault in one device’s APIs will not disrupt others
Partitioning vs. sharding
Having explained the concepts of partitioning and sharding, we will now highlight their differences.
Note: As mentioned above, sharding is a subset of partitioning where data is distributed over multiple machines. Therefore, when we refer to partitioning below, we refer to the partitions on a single machine.
Scalability
Scaling a server cluster is easy and flexible; you keep adding machines as the size of your data increases. Scaling a single machine, though, is comparatively difficult. Sharding, therefore, is more scalable than partitioning.
Availability
If a specific machine within a cluster goes down, only the queries dealing with that machine are affected. In the case of a single server, all data is impacted in the event of failure. Therefore, sharding has higher availability than partitioning.

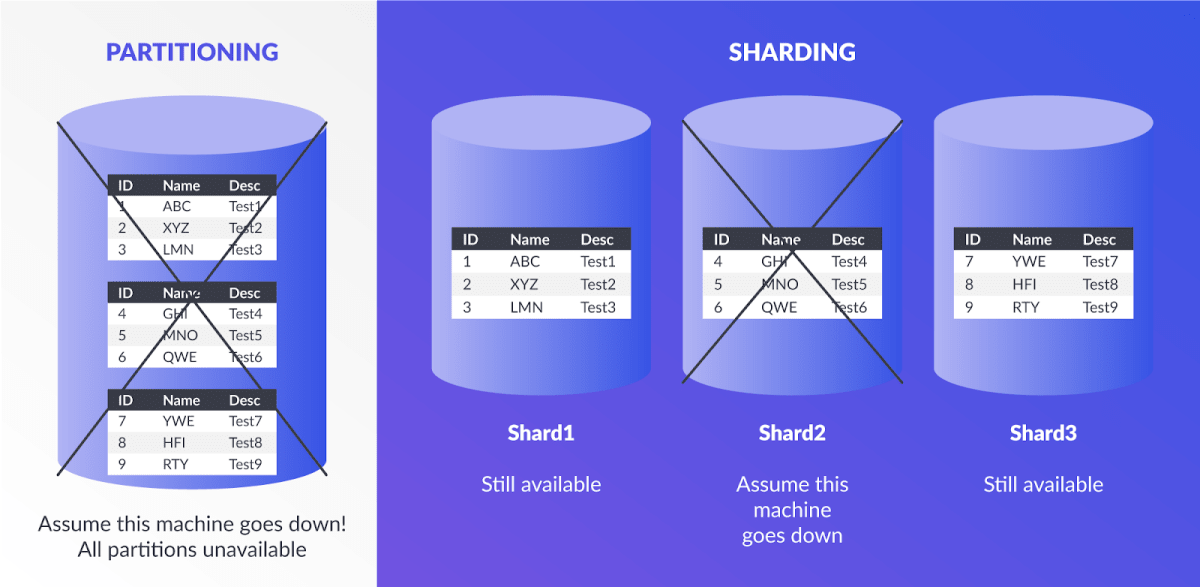
Image highlights the availability of partitioning when compared to sharding
Number of parallel queries
On a single machine, query parallelization is achieved via threads/processes. In turn, the number of available CPU cores dictates the number of threads/processes. Threads also share some common resources like RAM. In the case of multiple machines, each machine has independent CPU, RAM, and storage resources. Therefore, the queries are truly parallel (with no sharing of resources), and there is no upper limit on the number of parallel queries. Even if all your machines are single-core, you can still have as many parallel queries as you have machines.
Query time
Reducing query time is one of the fundamental reasons for sharding or partitioning, and both methods achieve this when compared to unpartitioned databases. However, in the case of partitioning, too many parallel queries on the database machine can choke the system and result in slowed performance.
With sharding, queries perform poorly when a single machine becomes overloaded. All other queries, however, will not be impacted. Therefore, query time is typically lower when sharding than partitioning.
Recommendations
When not to use sharding or partitioning
While sharding and partitioning are valuable techniques for better organizing data and speeding up queries, they may not always be necessary. For instance, sharding or partitioning may not be required if you have a small table containing just a few thousand rows. The entire table can be stored comfortably in one node.
Forcefully trying to partition/shard small tables may lead to performance penalties, as it involves additional steps to determine the correct shard/partition when inserting or querying data. In some cases, it will also increase the cost of maintaining the database. Thus, data should be partitioned/sharded only when the overhead is insignificant compared to the cost associated with querying an unpartitioned table.
As a rule of thumb, a table greater than 2 GB should always be considered for sharding or partitioning. If the table is less than 2 GB, you should decide based on current and expected query performance.
Choosing the shard key
When sharding or partitioning data, it’s vital that frequently accessed data is kept together. Consider a government statistics website. If users often query data for a particular pin code, using the pin_code field in your data or a broader field (like state_id) as the shard key makes sense. If you shard data based on an unrelated key, like metric, many queries will access multiple nodes, which is ineffective.
Conclusion
Both sharding and partitioning help improve query performance, especially for large bulky tables. They have several use cases and “misuse cases” if you are not careful. Sharding is a subset of partitioning (specifically, horizontal partitioning) and the critical difference is that different shards reside on separate machines or nodes. As a result, sharding has several advantages in terms of scalability, availability, parallelism, and query execution time. The use of either sharding or partitioning should first be considered judiciously, with thoughtful emphasis placed on selecting the shard key.
We hope that you have enjoyed this chapter and that it clarified any confusion you may have had surrounding sharding and partitioning.
Is your website ready for holiday shoppers? Find out.
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.