Stream Workers
A stream worker performs complex event processing on data in motion, also called streams. Macrometa GDN allows you to integrate streaming data and take appropriate actions.
Stream Processing
Most stream processing use cases involve collecting, analyzing, and integrating or acting on data generated during business activities by various sources.
| Stage | Description |
|---|---|
| Collect | Receive or capture data from various data sources. |
| Analyze | Analyze data to identify interesting patterns and extract information. |
| Act | Take actions based on the findings. For example, running simple code, calling an external service, or triggering a complex integration. |
| Integrate | Provide processed data for consumer consumption. |
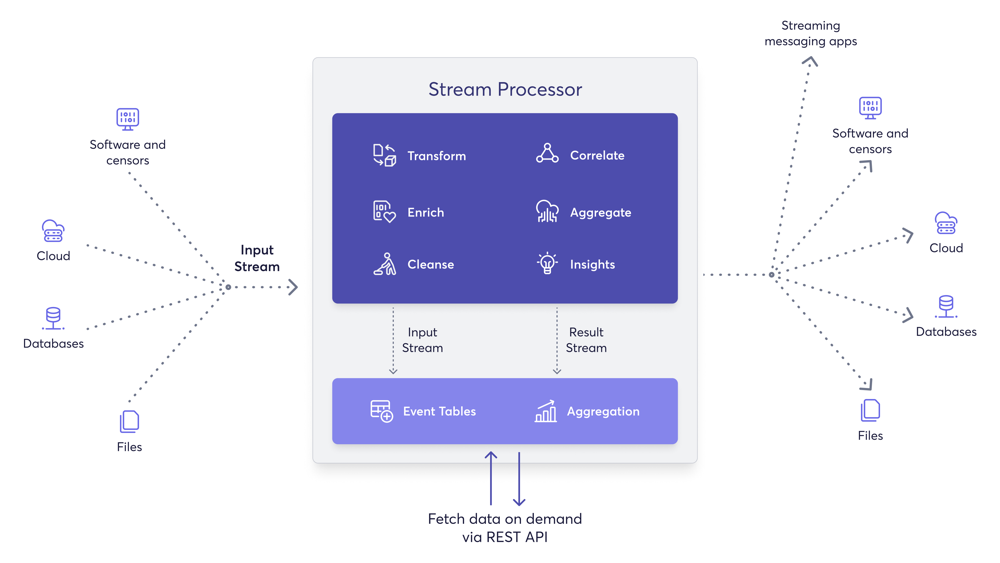
Stream Processing Actions
You can process streams to perform the following actions with your data:
- Transform data from one format to another. For example, from text to JSON.
- Enrich data received from a specific source by combining it with databases and services.
- Correlate data by joining multiple streams to create an aggregate stream.
- Filter data and events based on conditions such as value ranges and string matching.
- Clean data by filtering it and by modifying the content in messages. For example, obfuscating sensitive information.
- Derive insights by identifying event patterns in data streams.
- Summarize data with time windows and incremental aggregations.
- Extract, transform, and load (ETL) collections, tailing files, and scraping HTTP endpoints.
- Integrating stream data and trigger actions based on the data. This can be a single service request or a complex enterprise integration flow.
- Consume and publish events.
- Run pre-made and custom functions.
- Write custom JavaScript functions to interact with your streams.
- Query, modify, and join the data stored in tables which support primary key constraints and indexing.
- Rule processing based on single event using
filteroperator,if-then-elseandmatchfunctions, and many others.
These actions allow you to build robust global data processing and integration pipelines at the edge by combining powerful stream processing, multi-model database and geo-replicated streams capabilities.